역전파(Back-propagation) - 역전파 : Chain Rule을 통해 경사 계산을 작게 분해 후 결합하여 최종 기울기를 얻는 프로세스a 역전파는 신경망에서 사용할 가중치 계산에 필요한 기울기를 계산하기 위해 인공 신경망에서 사용하는 방법입니다. 네트워크 가중치에 대한 손실 함수의 기울기를 계산하기 위해 체인 규칙을 사용합니다. 목적 역전파의 목적은 네트워크의 가중치를 조정하여 손실 함수를 최소화하는 것입니다. 가중치에 대한 손실 함수의 기울기를 계산한 다음 이 기울기를 사용하여 손실을 줄이는 방향으로 가중치를 업데이트합니다. 사용: 역전파는 신경망의 훈련 단계에서 사용됩니다. Autograd Autograd는 Tensor의 모든 작업을 자동으로 구분하는 PyTorch 패키지입니다. 이것은 실행..
AI
- **실제 값과 예측 값의 차이를 제곱하여 평균** - 값이 작을 수록, 예측이 정확하다는 것이다 MSE는 예측이 실제 값에 얼마나 가까운지를 나타내며, 모델의 성능을 평가하는 데 중요한 지표입니다. 평균 제곱 오차(MSE)는 실제 값과 예측 값의 차이를 제곱하여 평균을 낸 것입니다. 이 값이 작을수록 예측이 실제 값과 가까워지며, 크면 클수록 예측이 부정확해집니다. 수식 n은 전체 데이터 포인트의 수 yi는 i번째 실제 값 ŷi는 i번째 데이터 포인트에 대한 예측 값 이는 모델이 예측하는 값이 실제 값에 가까워지도록 독립 변수의 계수를 조정하는 데 사용됩니다. 이러한 과정은 경사 하강법과 같은 최적화 알고리즘을 통해 이루어집니다. 부족한 점이나 잘못 된 점을 알려주시면 시정하겠습니다 :>
- 데이터 포인터를 계층적으로 분석해 클러스터링하는 방법 - 병합 클러스터링 : 하향식 - 분할형 클러스터링 : 상향식 계층적 클러스터링은 데이터 포인트들을 계층적인 클러스터나 클러스터의 트리 형태로 만들어가는 클러스터링 방법입니다. Intro 계층적 클러스터링에는 각 데이터 포인트를 초기에는 하나의 클러스터로 간주하고, 기존 클러스터를 계속해서 병합하거나 분할하는 과정을 거칩니다. 이 과정은 모든 데이터 포인트가 하나의 클러스터로 병합될 때까지 계속됩니다. 1. 병합형 계층적 클러스터링 이 방법은 하향식 접근법을 사용합니다. 각 데이터 포인트는 자신만의 클러스터에서 시작하여 단계별로 클러스터들이 결합됩니다. 결국에는 모든 데이터 포인트를 포함한 하나의 클러스터만이 남게 됩니다. 클러스터의 결합은 클러스..
Intro. 머신러닝 지도 학습(Supervised Learning) : 역사 : 독립 변수 | 종속 변수 독립 변수와 종속 변수로 모델을 만드는 것입니다 문제를 많이 풀면 점점 문제를 맞출 확률이 올라가는 것처럼 또는, 원인으로부터 결과를 도출 하고 싶을 때 사용합니다 과거의 데이터로 학습해서 결과를 예측하는데 올라간다 Regression(회귀) 모델 숫자를 알고 싶은 경우 https://bit.ly/ml1-regression-list : 회귀 사례 Classification 추측하고자 하는 것이 이름인 경우 https://bit.ly/ml1-class-list : 분류 사례 비지도 학습(Unsupervised Learning) : 탐험 : 데이터의 성격 파악 : 변수 | 변수 | 변수 기계에게 데이터..
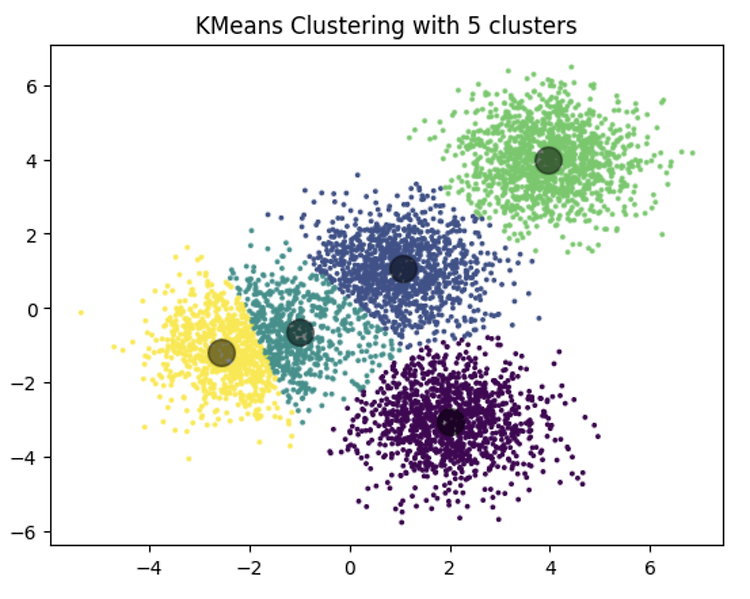
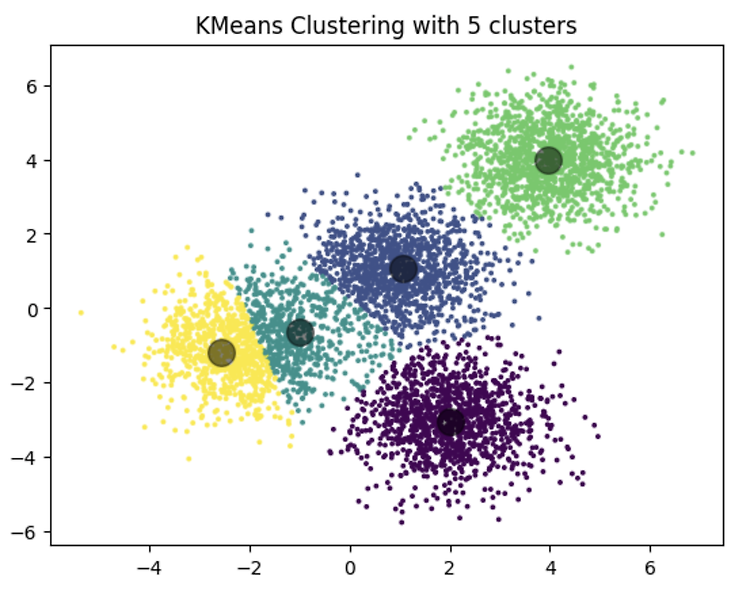
K - Means 알고리즘 실습 Intro 먼저 K-Means Clustering이 무엇인지, 그리고 어떤 실제 세계의 어플리케이션에서 사용되는지 살펴보겠습니다. K-Means는 군집화 모델 중 가장 단순한 모델 중 하나로, 그 단순함에도 불구하고 많은 데이터 과학 응용 프로그램에서 광범위하게 사용됩니다. 고객 세그멘테이션, 웹사이트 방문자의 행동 이해, 패턴 인식, 기계 학습, 데이터 압축 등에서 특히 유용하게 활용됩니다. 여기에서는 두 가지 예제를 통해 K-Means 클러스터링을 연습하게 될 것입니다. 무작위로 생성된 데이터셋에서의 K-Means 고객 세그멘테이션을 위한 K-Means 사용 1단계: 무작위 데이터셋 생성 먼저, 실습을 위한 데이터셋을 생성해 보겠습니다. 여기서는 numpy의 rando..
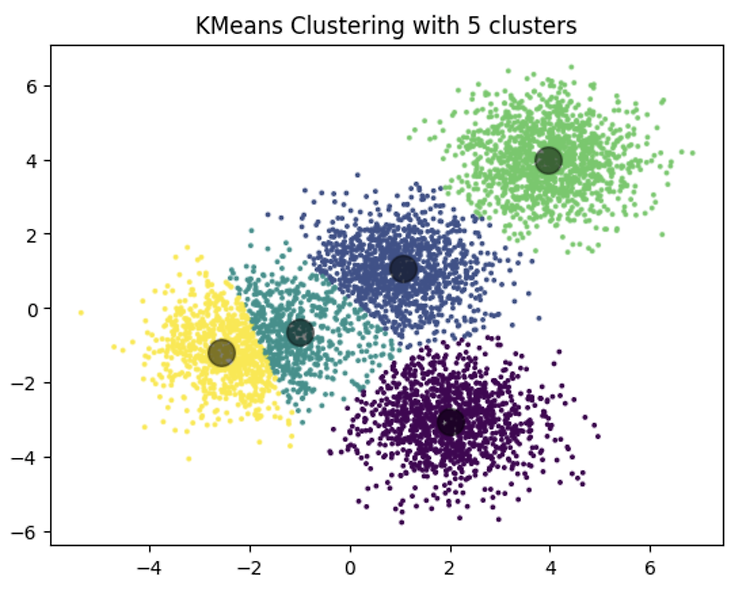
- 주어진 데이터를 여러 개의 상이한 그룹으로 분할한다 - 그룹 내 중심을 반복적으로 구해, 데이터 정밀도를 향상한다 K-Means 클러스터링은 비지도 학습(Unsupervised Learning)으로 Clustering을 하는 알고리즘이다. 이 알고리즘은 주어진 데이터를 여러 개의 상이한 클러스터로 그룹화한다 단계별 과정 : 반복 1. Set up Centroids 클러스터의 개수(K)를 결정합니다. K개의 클러스터 중심점을 무작위로 초기화합니다. 2. Distance Matrix 각 데이터 포인트(고객)를 거리에 기반하여 가장 가까운 클러스터 중심점에 할당합니다. 각 Centroid로부터 데이터 포인트의 거리를 Distance Matrix에 기록하고, 이를 중심으로 클러스터에 할당합니다 3. Clus..
Clustering - 물건들이 주어졌을 때 비슷한 것끼리 그룹을 만들면 군집화 - 관측치(행)를 그룹화하는 비지도 학습(Unsupervised Learning) 방법 물건들이 주어졌을 때 비슷한 것끼리 그룹을 만들면 군집화 관측치(행)를 그룹화하는 [[비지도 학습(Unsupervised Learning)]] 방법 클러스터링 알고리즘의 종류 분할 기반 클러스터링 이 알고리즘은 구형 클러스터를 생성합니다. 예로는 K-평균, K-중앙값, 퍼지 c-평균 등이 있으며, 이들은 대부분 효율적이며 중대형 데이터베이스에 사용됩니다. K-Means Clustering 계층적 클러스터링 이 알고리즘은 클러스터의 트리를 생성합니다. 예로는 병합 클러스터링과 분할 클러스터링이 있습니다. 이 알고리즘은 직관적이며 소규모 데이..
Support Vector Machine - 데이터를 고차원 공간으로 맵핑하여, 데이터를 구분하는 알고리즘 - 초평면을 그린다 - 데이터를 정확히 분류하는 범위를 찾고, Margin을 최대화 되도록 구분 SVM (Support Vector Machine)은 Classification를 위한 Machine Learning 방법 중 하나입니다. SVM은 지도 학습(Supervised Learning)으로, 분류 문제에서 케이스를 구분하는 분리자를 찾아서 케이스를 분류합니다. SVM은 데이터를 고차원 특징 공간으로 매핑하여 데이터가 선형적으로 분리되지 않는 경우에도 카테고리별로 분류할 수 있도록 합니다. 그런 다음, 데이터를 위한 분리자를 추정합니다. 데이터는 분리자를 초평면으로 그릴 수 있도록 변형되어야 합..
- 0 ~ 1 사이의 결과 값으로 확률을 모델링 할 때 사용 된다 - [[Logistic Regression]]에서 종속 변수 확률 예측하는데 사용 된다 시그모이드 함수는 이름에서 알 수 있듯이 ‘S’ 형태의 곡선을 가지는 함수를 의미하며, 여기에서 'S’는 "시그모이드(Sigmoid)"의 'S’입니다. 수학적으로 표현하면 아래와 같습니다. Sigmoid 함수와 로짓 함수의 관계 일단 서로 역함수 관계입니다. 즉, 로지스틱 함수가 0과 1 사이의 값을 출력한다면 로짓 함수는 0과 1 사이의 값을 입력으로 받아서 실수 값을 출력합니다. 로지스틱 함수는 실수 값을 0과 1 사이의 값으로 '압축’하는 역할을 합니다. 반면에 로짓 함수는 0과 1 사이의 확률값을 다시 실수 값으로 ‘펼쳐’ 놓습니다. 부족한 점이..
- [[이진 분류]]하는 상황에서 자주 사용한다 로지스틱 회귀는 종속 변수가 이진 변수인 경우를 다루는 통계 기법입니다. 로지스틱 회귀는 독립 변수의 선형 결합을 이용하여 사건의 발생 가능성을 예측하는데 사용됩니다. 이 방법은 Linear Regression과 매우 유사하지만, 로지스틱 회귀는 종속 변수가 범주형이고 선형 회귀는 종속 변수가 연속형이라는 점에서 차이가 있습니다 예시로 10년 후의 지구 온도는 어떻게 될까는 Linear Regression이고, 10년 후의 지구 온도가 50도 이상일까?는 Logistic Regression이다. 손실 함수 (Loss function) 이진 분류 문제(binary classification problem)의 경우 다중 클래스 분류 문제(multiclass c..